URL Shorteners are used to create short aliases for long URLs. When a client clicks on a short link, it will be redirected to the original URL. The most popular example is TinyURL.
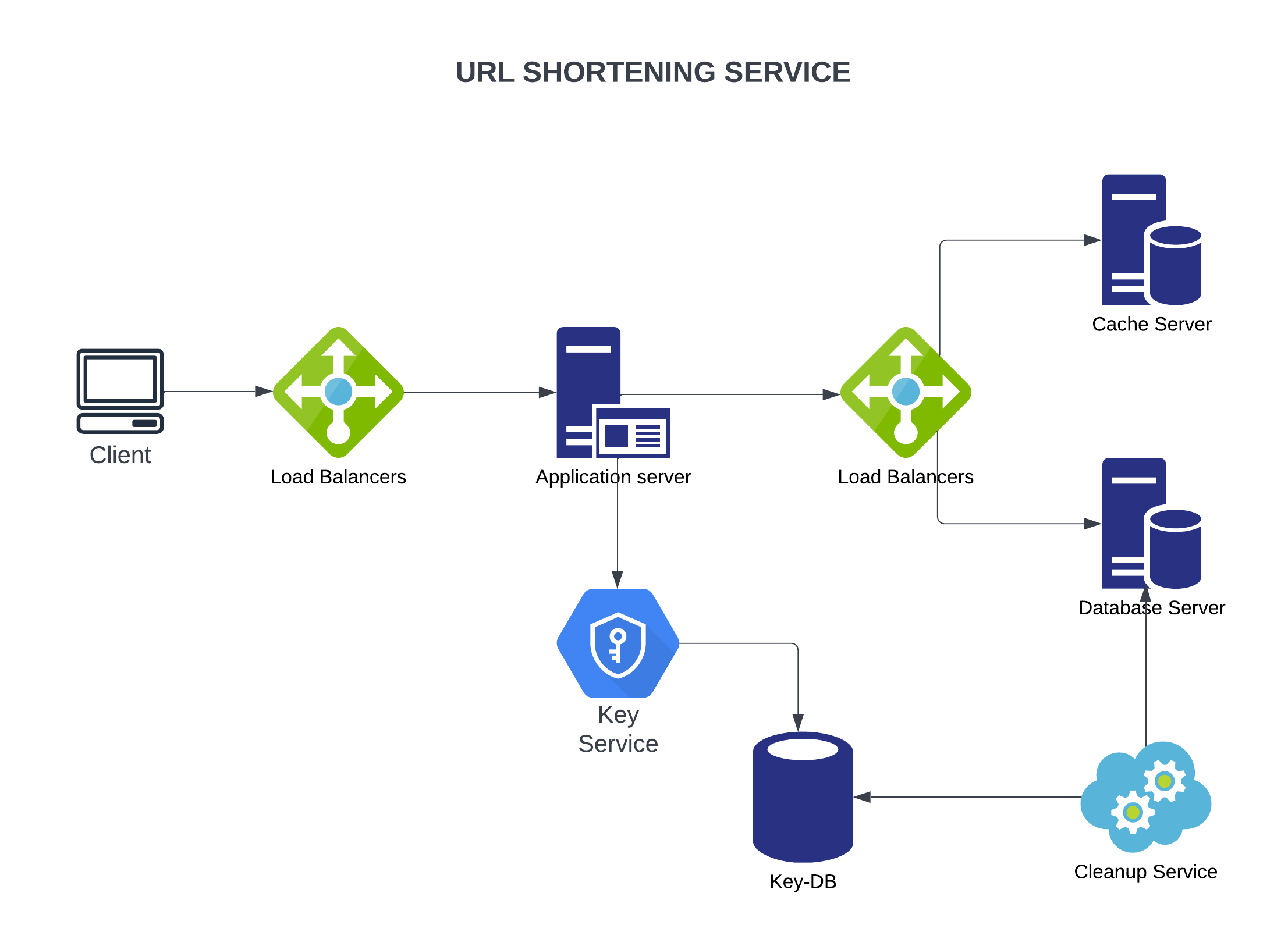
Overall Design
Functional Requirements
- Given a full URL, service should return a short link.
- When a user clicks on a short link, service should redirect them to the original URL.
- Users should be able to define custom aliases.
- Users should be able to define expiration time.
- Short links should be human readable.
- A short link will be stored in database for 5 years.
- There will be 500 millions of create request per month with 100:1 read ratio.
Non-functional Requirements
- The system should be available with rate %99.9.
- Redirection should be instant with minimum latency.
- Short links should not be guessable.
Extra
- Should provide analytics for various metrics that can be collected.
- Should provide an API that allows other services to integrate.
Database Design
URL Table:
| Variable | Type |
|---|---|
PK |
varchar(16) |
original URL |
varchar(2000) |
creation date |
datetime |
expiration date |
datetime |
user ID |
int64 |
So, for each item in URL table, we will need roughly 2040 bytes.
User Table
| Variable | Type |
|---|---|
user ID |
int64 |
name |
varchar(32) |
creation date |
datetime |
last login |
datetime |
For each item in User table, we will need roughly 60 bytes.
What kind of database to use
Since we do not need relations between objects and we store billions of records, it would be better to use a NoSQL database such as DynamoDB or Cassandra. This will make it easier to scale.
System Estimations
Traffic
With 500 million requests per month with 100:1 ratio, we will have 50 billions read requests per month. In terms of seconds:
500 millions / (30 days * 24 hours * 3600 seconds) = ~200 URLs/s will be created. ~200 URLs/s * 100 = 20,000 URLs/s will be redirected.
Storage
Since we expect 500 millions requests per month and they will be stored for 5 years:
500 millions * 5 years * 12 months = 30 billion URLs will be stored.
Assume we set a upper bound on original URL length as 2000 characters, because the minimum length supported by all browsers is 2047.
In the worst case, each user creates only one short link, so we will have one-to-one relation between URLs and users. From previous section each pair of items requires 2100 bytes of storage.
30 billion requests * 2100 bytes = 62 TB of storage needed.
Bandwidth
Since we expect 200 request/s for create requests:
200 * 2100 bytes = 420 KB/s
For read requests:
20,000 * 2000 bytes = 40 MB/s
Memory
If we want to cache some URLs that are frequently accessed. Assume that %20 of URLs are accessed frequently, we should cache those %20:
20,000 read requests * 3600 seconds * 24 hours = 1.7 billion requests per day 0.2 * 1.7 billions * 2000 bytes = 680 GB of cache needed.
However, since there will be many duplicate requests for the same URL, required cache size will be much smaller than expected.
API Design
User Related:
POST /signup returns user ID and session token.
POST /login returns a session token.
URL related:
GET /<short_link> redirects to the original URL.
POST /links creates and returns a short link.
PUT /<short_link> updates short link, e.g. expiration time or custom alias.
DELETE /<short_link> deletes short link.
Since we keep user ID inside URL record, we can give a session token to the authenticated user for operations except redirections. Also, we can set a rate limit for users to prevent malicious attacks.
System Design
Short Link Length
As a requirement, short links must be human readable. So, we should avoid to use non-alphanumeric characters. Let’s say we use [0…9], [a…z], [A…Z], so we have 10 + 26 + 26 = 62 characters key set.
We know that for 5 years, we need at least 30 billions of short links. If we use base62 encoding:
62^5 = ~917 million short links can be generated. 62^6 = ~57 billion short links can be generated.
So, 6 characters are enough for generating short links for our service.
Custom Aliases
To maintain a consistent database, we can set an upper limit on custom alias length, assume it is 16 characters with the same key set described above.
Key Generation
We can pre-generate all possible keys and store them in a seperate key-value store, we can call it key-DB.
Then, we can create a standalone key service so whenever we want to shorten a URL, we can get one of the already generated keys to use it. We can ensure that all inserted short links are unique.
As soon as a key is used, we should mark it as used to ensure it will not be used again. So, servers will not be editing key-DB directly but request read/mark key service. Key service can store two tables, one for active keys and one for used keys. As soon as key service provides a short link, it can move that item to the second table.
Also, key service can store some short links in-memory and move those keys to the second table beforehand. In this way, we can fasten key requests and even if key service dies before using all keys in memory, it will not be problem because we have more than enough possible keys.
Key service also has to guarantee it is not giving the same key to multiple servers. So, it should use a lock or queue structure to ensure uniqueness.
Key-DB Size
6 characters * 57 billion keys = 342 GB storage is needed.
Single Point of Failure
To avoid SPF, we can have a replica of key service and key-DB. If the main key service dies, the replica can continue to generate and provide short links.
Can application servers store keys in-memory?
To fasten our service, applicaation servers can store short links beforehand to respond fast. Even though a server dies before using all keys, it will be acceptable since we have 57B unique keys.
How to perform a key lookup
First we hash short link to find which partition key belongs to. Then, we check if key exists on database. If found, we use HTTP 302 Redirect to redirect to the original URL. If not found, we return HTTP 404 Not Found error.
Scaling
We should scale according to both data storage and web traffic to provide minimum latency and high availability.
Data Partitioning
To scale out our database, we can partition it so that it can store billions of records and still querying is fast.
We can define a hash function that produces a value between [1...256] for a given key. Key in this context can be short link. Our hashing function should distribute all keys evenly for each partition.
To prevent some partitions to be overloaded, we can use Consistent Hashing
Caching
As we discussed earlier, we can cache frequenty accessed URLs which required 680 GB memory at worst but can be around 500 on average. We can set up a couple of Redis servers to store all of this data. In this context, LRU eviction policy would be a good choice.
We can also replicate our caching servers to distribute load between them.
Whenever there is a cache miss, our servers would be hitting the database. Whenever this happens, we can update the cache and pass the new entry to all the cache replicas. Each replica can update its cache by adding the new entry. If a replica already has that entry, it can simply ignore it.
Load Balancing
We can add load balancing between:
- Clients and application servers
- Application servers and database servers
- Application servers and cache servers
We have modern solutions on load balancing, Knative can be used in clusters to manage load balancing between pods.
Database Cleanup
Instead of keeping expired links forever, we can cleanup expired links, like after 5 years, to shrink database volume.
We can use a cleanup service that periodically scans over database and deletes expired links. After an expired short link is deleted, we can put that short link into key-DB for reuse.
Extras
Analytics
We can set up a stream such as AWS Kinesis and fire events for analytics. Also, we can set up a metrics service such as Prometheus or Datadog for detailed metrics including web traffic, response statuses, average response time and service availability.
Security
We can provide a session token for operations on URLs that is expired after a period. Also, rate limiting users protects our service and database from unexpected workload. In addition, we can allow users to define access control on short links and return 401 for unauthorized clients.