Autocomplete services are used to list the most relevant searches based on what a user typed so far. For example, when you use Google search, for each key you entered, Google lists a bunch of relevant searches that are frequently queried by other users.
Overall Design
Functional Requirements
- Service should return a list of 5 suggestions based on what user types on the search box.
- Results should be ordered by frequency of their appearance in the previous searches.
- Results must be real-time, i.e. new queries must be saved.
Non-functional Requirements
- Service should be highly available.
- Service should be scalable to handle billions of queries per day.
- Service should provide results in real-time, as a user types in search box.
- Service should be partition tolerant.
System Estimations
Traffic
Assuming our service handles 5 billion queries per day. Assuming each query consists 3 words on average. Assuming each word in a query consists 5 characters on average.
Then:
3 words * 5 characters = 15 read requests per query
15 requests per query * 5 billion queries = 60 billion requests per day
60B requests per day / (24 hours * 3600 seconds) = ~700K read requests per second
Storage
It takes 2 bytes to store one character.
15 characters * 2 bytes = 30 bytes per query
There will be many duplicate queries, assuming only 30% of queries per day are unique.
1.5 billion queries * 30 bytes = 45 GB storage per day
45 GB * 365 days = ~16 TB storage per year
~160 TB storage needed in 10 years
Bandwidth
Since we return the top 5 results, and assuming each result consists 15 characters on average.
~700K requests per second * 5 results * 30 bytes = 100 MB/s bandwidth required.
API Design
-
get_suggestions(prefix string)returns a list of 5 top suggestions. -
save_query(query string)submits a query to service.
High Level Design
To give the most frequent 5 suggestions in real-time, our service should have two parts:
- Giving related suggestions
- Adding new queries to database
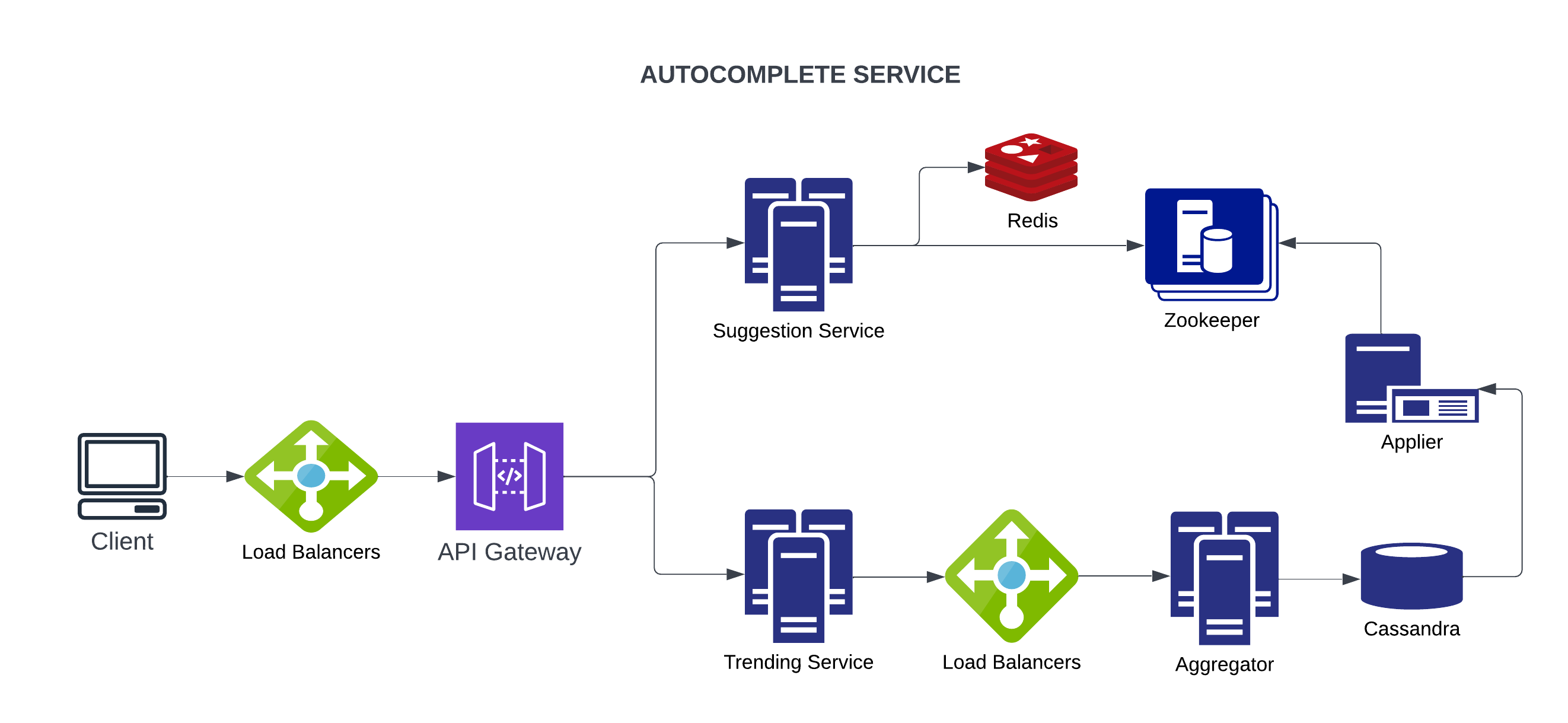
When a user starts typing, after each keystroke, we should call get_suggestions() to retrieve 5 suggestions from database. So, we should have a microservice called Suggestions Service which handles suggestion requests.
When user clicks on enter, that query must be saved in our database to compute frequency and be available to suggest to other users. So, we should have a microservice called Trending Service which will writes queries to database.
We are receiving 700K requests per second, obviously one server cannot be enough. So, we have a cluster for each of suggestions and trending services. Then, we can use load balancers to distribute workload between nodes. We can use consistent hashing to distribute work evenly.
We then add an API gateway to ensure each request redirected to the correct microservice.
Database Design
Trie is a data structure that is mostly used for prefix search. It gives search time complexity O(L) where L is the height of trie.
In order to optimize space, we can merge nodes that have only one branch. Also, we can keep frequency of each query within a Trie node.
With Trie, the time complexity of returning results is:
O(L)for search prefix,O(n)for scanning subtree under prefix, where n is the number of nodes.O(nlogn)for sorting results to get the top 5 suggestions.
Since we are seeking for real-time suggestions, this will not be sufficient.
One way to reduce latency is to precompute the top 5 suggestions for each prefix and store them in a cache such as Redis. This means, instead of traversing trie each time user enters a new key, we just retrieve items from a cache.
Since we prioritize availability, partition tolerance and scalability, and also we do not need structured data, it is logical to use NoSQL databases such as Cassandra.
Update Trie
We can store logs of queries and their frequencies in a hash table aggregated by hour or day. Let’s say we have a microservice called Aggregator. Aggregator collects queries and aggregates them in a hash table stored in a database such as Cassandra.
There are two optimizations on this:
- We can discard entries older than a specific time period, such as a month. We can discard frequencies stored in hash table older than a month.
- We can set up a threshold and discard entries with lower frequency than the threshold. Let’s say 100 queries for an hour.
Then, let’s say we have another microservice called Applier. Applier service fetches entries from Cassandra every hour and builds a new Trie with them. Once the new Trie is ready, Zookeeper drops old trie and uses the new one.
Optimizations
Now, we know that Trie is the best option for prefix search. However, if we have only one database server and if it goes down, our service will be unavailable. Since we want our service to be highly available, our Trie will be replicated through multiple servers. if one server goes down, or is overloaded with requests, the other nodes that carry the same information can continue serving the requests. Replicating the information across multiple nodes also makes the system reliable since even if a node is lost, the autocomplete information is not lost and can be accessed from the other storage servers. The replicated instances of trie can be stored in Apache Zookeeper. Zookeeper is a good choice for storage since it is highly available and can effectively serve high volumes of reads and some writes. You can also use a different distributed database, such as Cassandra for the purpose.
Further, we can split trie into multiple nodes each covers a different range of characters. For example, if we split trie into 3 parts and each part is handled by multiple database servers, then we can handle requests faster. We can increase the number of splits according to our resources. This can be called sharding, we can partition our trie for each alphabet. However, we should keep a replica or a snapshot of each shard so that we can recover any server failure. This can be handled by Cassandra easily,
To avoid unbalanced workload on each database server, we can assign different servers to different range of prefixes and use consistent hashing to distribute workload evenly.
In addition, We can cache popular searched prefixes. According to the 80-20 principle, 20% of search queries generate 80% of the traffic. Thus, we will cache these popular search queries so that the application servers will first check cache servers before hitting the trie servers. We can use Redis for the same.